아래는 GTC 2025 엔비디아 대표 젠슨황의 키노트를 최대한 많이 담은 글입니다.
GTC에 오신 것을 환영합니다. 정말 놀라운 한 해였죠. 우리는 이 발표를 엔비디아에서 하고 싶었습니다. 그래서 인공지능의 마법을 통해, 여러분을 엔비디아 본사로 모셔오려 합니다. 보시다시피, 제가 엔비디아 본사로 여러분을 모시고 온 것 같네요. 어떠신가요? 바로 우리가 일하는 곳입니다. 우리가 일하는 곳이 바로 여기입니다. 정말 놀라운 한 해였고, 오늘 이야기할 멋진 것들이 많습니다. 말씀드리고 싶은 게 아주 많아요. 우선, 대본이나 프롬프터가 없고 안전장치도 없이 이 자리에 서있다는 점을 아셔야 합니다. 커버해야 할 내용이 아주 많으니 시작해봅시다. 먼저 모든 스폰서와 이 컨퍼런스에 참여해주신 분들께 감사드립니다. 거의 모든 산업 분야가 참여했어요. 헬스케어, 운송, 유통, 그리고 컴퓨터 업계—컴퓨터 업계는 모조리 와있습니다. 정말 반갑고, 스폰서해주신 모든 분들께 감사의 말씀을 드립니다.
GTC는 지포스(GeForce)에서 시작되었습니다. 모든 것은 지포스로부터 시작되었죠. 오늘 이 자리에 지포스 5090이 있습니다. 25년 전, 우리가 지포스를 개발하기 시작한 뒤로, 믿기 힘들지만 25년이 지난 지금 지포스는 전 세계적으로 매진되며 엄청난 인기를 누리고 있습니다. 이것이 바로 90, 즉 블랙웰(Blackwell) 세대 제품입니다. 49(4090) 제품과 비교하면, 부피가 30% 더 작고, 에너지 소모량도 30% 더 효율적이며, 성능은 말도 못 하게 우수합니다. 그 이유는 바로 인공지능 때문이죠. 지포스가 쿠다(CUDA)를 세상에 가져왔고, 쿠다는 인공지능(AI)을 가능하게 했으며, 인공지능이 다시 컴퓨터 그래픽스를 혁신하게 된 것입니다. 지금 보시는 것은 실시간 컴퓨터 그래픽스로, 픽셀마다 100% 패스 트레이싱(path tracing)을 거쳤습니다. 인공지능이 나머지 15픽셀을 예측해낸다는 점을 한번 생각해보세요. 한 픽셀을 수학적으로 렌더링할 때마다, 인공지능이 추가로 15개의 픽셀을 추론합니다. 그것도 결과물이 정확한 이미지를 유지해야 하고, 동시에 프레임 간 시간적 안정성(temporal stability)도 유지되어야 합니다. 즉, 컴퓨터 그래픽스에서 프레임 전후로도 시각적으로 안정적이어야 하죠. 정말 놀라운 발전입니다.

인공지능은 엄청난 진전을 이뤄왔습니다. 불과 10년밖에 지나지 않았어요. 물론 그 전부터 AI 이야기를 해오긴 했지만, 전 세계적으로 AI가 주목받게 된 것은 약 10년 전부터였습니다. 최초에는 인식(perception) AI—컴퓨터 비전과 음성 인식부터 시작되었습니다. 이후 5년 전부터는 생성형(generative) AI에 주력하게 되었죠. AI에게 텍스트를 이미지로, 이미지를 텍스트로, 텍스트를 영상으로, 아미노산을 단백질로, 물성(properties)을 화학물질로 바꾸도록 가르치는 식입니다. AI를 활용해 각종 컨텐츠를 생성해내는 다양한 방법이 개발되고 있습니다. 생성형 AI는 컴퓨팅의 방식을 근본적으로 바꿔놓았습니다.
이전에는 ‘검색 기반(retrieval-based) 컴퓨팅’ 모델로 작업했다면, 이제는 ‘생성 기반(generative) 컴퓨팅’ 모델이 되었습니다. 과거에는 컨텐츠를 미리 만들어 여러 버전으로 저장해두고, 사용 시점에 맞춰 적절한 버전을 가져와 쓰는 방식이었죠. 하지만 이제 AI는 맥락(context)을 파악하고, 우리가 묻는 내용을 이해하며, 요청의 의미를 해석한 뒤 자기 지식 바탕에서 답을 생성합니다. 필요한 경우 정보를 검색해 이해를 보충한 뒤, 답변을 만들어내요. 말 그대로 ‘데이터를 검색’하는 대신, ‘해답을 생성’하는 시대가 된 것입니다. 이는 컴퓨팅을 근본적으로 바꿔놓았고, 최근 몇 년간 컴퓨팅의 모든 레이어가 변화하고 있죠.

그리고 지난 2~3년 사이, 인공지능 분야에서는 또 다른 메이저 브레이크스루가 있었습니다. 우리는 이를 ‘에이전틱(Agentic) AI’라고 부릅니다. 에이전틱 AI란, 스스로 행위할 수 있는 능력(agency)이 있는 AI를 말합니다. 즉, 상황(context)을 파악하고, 문제 해결 방법을 스스로 고민하며, 계획을 세워 실행할 수 있는 능력입니다. 더 중요한 것은, 이 AI가 도구(tools)를 사용할 수 있다는 점이죠. 요즘 AI는 멀티모달(multimodality)을 이해하기에, 웹사이트에 접속해 구조나 단어, 동영상을 파악하고 직접 플레이하여 배웁니다. 그런 뒤 배운 지식을 활용해 자기 일을 수행할 수 있습니다. 에이전틱 AI의 핵심은 바로 ‘추론(reasoning)’에 있습니다. 그리고 이미 우리 눈앞에는 그 다음 물결이 오고 있어요. 오늘은 이 이야기를 자세히 해보겠습니다.

“에이전틱 AI의 또 다른 중요한 전망은 로보틱스 분야입니다. 물리적 AI(physical AI)라는 개념으로, 물리적 세계를 이해하는 AI가 로보틱스를 가능케 합니다. 마찰이나 관성, 인과관계, 물체의 지속성(object permanence) 같은 개념을 이해해야 하죠. 어떤 모서리를 돌았다고 해서 완전히 이 우주에서 사라지는 건 아니라는 사실 같은 것을 알고 있어야 합니다. 그렇기 때문에 3차원 세계를 인식하는 물리적 AI가 있어야 로보틱스의 시대가 열립니다.
각 단계마다 새로운 시장 기회들이 열리고, 그에 따라 GTC에 참여하는 분야와 업체도 해마다 증가합니다. 이제는 헬스케어나 운송, 유통뿐 아니라, 정말 모든 산업 분야가 함께합니다. 올해는 에이전틱 AI와 물리적 AI를 많이 다룰 것이고요.
핵심적으로, 각 AI의 물결과 단계가 가능해지려면 세 가지 난제를 풀어야 합니다. 첫째, 데이터 문제를 어떻게 해결할 것인가. AI는 데이터 기반의 컴퓨터 과학 접근 방식이므로, 학습할 데이터를 대규모로 확보해야 합니다. AI가 지식을 얻고 디지털 경험을 쌓는 데 필요한 데이터가 어디서 오는지가 중요합니다.
둘째, 어떻게 인간이 간섭하지 않아도(‘human in the loop’가 아닌) 스스로 학습하게 할 것인가. 사람의 시간을 투입해 시연해주거나 레이블링하는 방식으로는 AI가 슈퍼 실시간으로, 그리고 초인적인 규모로 학습하기 어려우니까요.
셋째, 어떻게 확장성(scalability)을 확보할 것인가. 자원이 늘어날수록 AI가 점점 더 똑똑해지는 ‘스케일링 법칙(scaling law)’이 실제로 작동하게 만들어야 합니다. 작년까지도 많은 이들이 잘못 예측한 부분이 바로 이 세 번째 지점입니다. 모든 것이 아주 빠르게 변했거든요.
특히, 에이전틱 AI와 추론(reasoning)의 등장으로 인해서, 우리가 1년 전 예측했던 것보다 실제로는 100배 이상의 연산량이 필요하게 됐습니다. 이 부분을 조금 더 풀어서 말씀드릴게요.
먼저, AI가 할 수 있는 일을 보죠. 에이전틱 AI의 핵심은 앞서 말했듯이 추론입니다. 이제는 스스로 단계를 쪼개어 문제를 해결하고, 최적의 답을 도출하거나, 동일 문제를 여러 방식으로 해결해본 뒤 최적의 해를 골라내고, 심지어 답을 추론한 뒤 다시 검증해볼 수도 있습니다. 예전에 챗GPT가 처음 나왔을 때는 질문을 하면 한 번에 답변을 ‘툭’ 내놓았지만, 지금은 한 단계씩 사고 과정을 거치는 ‘Chain of Thought’ 기법을 적용하는 등, 훨씬 깊게 추론하는 AI가 등장했습니다.

그러니 토큰(token) 발생량이 폭증합니다. 과거에는 질문을 넣으면 한 번에 답을 생성했지만, 이제는 단계별 사고 과정을 전부 토큰으로 표현합니다. ‘1단계’ 내용을 토큰으로 생성해내고, 그 결과를 다시 입력으로 넣어 2단계를 생성하고… 이런 식으로 계속 이어지니, 토큰 수가 엄청나게 늘어나는 거예요.

그럼 이렇게 늘어난 토큰이 어떤 의미가 있을까요? 예를 들어, 100배까지 늘어났다 칩시다. 그러면 10배 정도 늘어난 토큰 수를 감당하려면, 모델의 응답 속도를 사용자가 참을 수 있을 정도로 유지하기 위해 10배 더 빠른 계산 능력이 있어야 하죠. 결국 10x와 10x가 겹쳐서 100배 이상의 연산량이 필요해집니다.

이처럼, 에이전틱 AI 시대에는 추론 단계가 엄청난 연산을 요구합니다. 다음으로, 그럼 AI에게 어떻게 이런 추론 과정을 학습시키느냐가 문제입니다. 앞서 말한 대로 두 가지 난제가 있는데, 어디서 데이터가 오느냐, 그리고 어떻게 인간이 없어도 학습할 수 있느냐죠.
우리가 찾은 해법은 강화학습(reinforcement learning)과 검증 가능한 결과(‘verifiable results’)입니다. 요즘은 ‘인간 시연(human demonstration)’처럼 사람이 답을 가르쳐주는 방식을 넘어, AI 스스로 수많은 예시를 가지고 문제를 풀어보도록 하고, 잘 풀렸다면 보상을 주는 식으로 스스로 학습하도록 할 수 있게 됐습니다. 세상에는 이미, 답이 확실하고 풀이 과정까지 우리가 아는 문제들이 엄청나게 많습니다. 일례로 수학이나 기하학, 논리, 게임 퍼즐 등 수백 가지의 문제 영역이 있고, 각 분야에 대해 수백만 개의 예시를 만들 수 있어요. AI는 수십만~수백만 번 문제를 풀어보면서 점진적으로 나아집니다.
이 과정에서, 토큰은 다시 한 번 폭증합니다. 단계별 추론 내용을 모두 토큰으로 기록하니까요. 그래서 결과적으로, 학습 단에서 수조(兆) 단위를 넘어서는 엄청난 토큰이 필요해집니다.

이렇게 계산량이 폭발적으로 증가함에 따라, 1년 전에는 AI 인프라가 어느 정도면 되겠다고 생각하던 것이 완전히 뒤집혔어요. 그 결과 우리 업계가 엄청난 규모로 GPU 기반 인프라 구축에 나서고 있습니다. 제가 지금 보여드리고 싶은 그림이 있어요. 호퍼(Hopper) 아키텍처, 즉 H100이 4대 CSP(클라우드 서비스 제공업체)에서 출하되는 추이인데, 정확히 말씀드리면 아마존, 애저(Azure), 구글 클라우드, 오라클 OCI 이 4곳의 데이터를 보고 있습니다. 여기에 전문 AI 기업들이나 스타트업, 엔터프라이즈, 기타 다양한 부분은 포함 안 했고요. 그런데도 불과 1년 만에 출하량이 이렇게 껑충 뛰었습니다.
이는 AI가 워낙 유용해졌기 때문입니다. 우리가 매일 접속하는 챗GPT만 해도, 갈수록 사용이 증가해 대기 시간이 길어지고 있잖아요. 많은 사람들이 정말 효율적으로 사용하고 있고, 그만큼 연산량 수요가 늘었습니다. 학습(트레이닝)에서도 점점 더 큰 모델을 더 많이 학습해야 하니 계속 투자가 늘고 있고요.

이런 경향은 컴퓨팅 전반으로 퍼져나가고 있습니다. 자본 시장 분석기관들의 예측치를 보면, 세계 데이터센터 건설비가 앞으로 계속 급증해 2030년 즈음에 1조 달러(약 1,300조 원)에 이를 것으로 보이는데, 그 흐름이 이미 가시화되었습니다. 전통적인 ‘범용 컴퓨팅(general-purpose computing)’ 방식이 한계를 맞으면서, 기계학습용 가속 컴퓨팅(accelerated computing) 방식이 자리 잡고 있습니다. 즉, 코드로 로직을 짜던 시대에서, 모델이 스스로 로직을 익히는 시대가 되고 있는 거죠.
이제는 검색 기반 컴퓨팅이 아니라, 토큰을 생성해 솔루션을 만들어내는 AI 팩토리(AI factory)로 변모하고 있습니다. 데이터센터를 짓는 목적도 달라졌어요. 예전에는 여러 기업과 사용자를 위해 웹 서비스나 애플리케이션을 호스팅하기 위한 인프라였다면, 이제는 ‘토큰을 대량 생산하는 공장’이 된 겁니다. 모델이 토큰을 뽑아내고, 우리는 그 토큰을 재조합해 텍스트, 음악, 영상, 화합물 등 다양한 형태로 활용합니다.
“그렇다면 모든 데이터센터는 가속화(accelerated)될 것입니다. 물론 모든 것이 AI는 아니지만, 어떤 식으로든 엔비디아의 가속 컴퓨팅 방식을 사용하게 될 거예요. 여기서 매우 중요한 점이 있는데, 이 슬라이드는 우리에게 매우 상징적인 그림입니다. GTC를 꾸준히 참가해오신 분들은 익히 보셨을 겁니다. 엔비디아가 지금껏 발표해온 수많은 라이브러리(CUDA-X 라이브러리)들이 바로 이 그림 하나에 다 담겨 있거든요.

보시는 첫 번째 아이콘은 ‘cuNumeric’로, 넘파이(numpy)를 GPU로 가속해주는 라이브러리입니다. 넘파이는 파이썬에서 가장 많이 쓰이는 라이브러리죠. 연간 4억 건 이상의 다운로드가 이루어집니다. 그런데 cuNumeric을 사용하면, 아무런 소스 코드 변경 없이 넘파이 코드를 가속화할 수 있어요.
‘cuLitho’는 반도체 공정에서 가장 중요한 단계 중 하나인 컴퓨테이셔널 리소그래피(computational lithography)를 가속화해주는 라이브러리입니다. 거의 4년에 걸쳐 TSMC, 삼성, ASML, 시놉시스, 멘토 등과 함께 협력해왔는데, 이제 반도체 공정에 있어 이 기술은 ‘Tipping Point(전환점)’를 맞았습니다. 앞으로 5년 안에 거의 모든 마스크(mask) 공정이 엔비디아 쿠다 기반으로 처리될 거라고 봅니다.
‘Aerial’은 5G 라이브러리로, GPU 하나로 5G 라디오 기능을 수행하게 해줍니다. AI를 결합한 ‘AI RAN(Radio Access Network)’을 구축할 수 있도록 하죠. 여기에 ‘cuOpt’는 조합 최적화(optimization) 라이브러리로, 운항 스케줄, 재고·고객 관리, 기사 배차 등, 복잡한 제약이 많은 문제를 빠르게 풀도록 도와줍니다. 우리 엔비디아도 자사 공급망 관리에 활용 중입니다. 전통적으로는 몇 시간, 심지어 며칠이 걸리던 계산이 수 초, 수 분 안에 끝납니다.
‘Parabricks’는 유전체(genomics) 분석 및 시퀀싱을 위한 라이브러리고, ‘MONAI’는 의료 영상 분석을 가속화합니다. ‘Earth-2’는 기상 시뮬레이션 등 멀티피직스(multiphysics) 모델을 다루고, ‘cuQuantum’과 ‘CUDA-Q’는 양자 컴퓨팅 연구 및 하이브리드 양자-클래식 시스템 개발을 지원합니다. 각종 라이브러리가 정말 다양하죠.
‘cuTensor’, ‘cuChem’ 같은 양자 화학(quantum chemistry) 가속 라이브러리도 있고, 곧 출시할 sparse(희소행렬) 솔버 ‘cuDSS’는 CAE(Computer-Aided Engineering) 분야를 가속화합니다. 설계·시뮬레이션 작업이 훨씬 빨라져요. ‘cuDF’는 데이터프레임용 라이브러리로 구조화된 데이터를 GPU에서 처리하고, 판다스(pandas) 등을 거의 수정 없이 가속할 수 있게 합니다.
이처럼 쿠다(CUDA) 위에 얹혀진 라이브러리는 일종의 ‘SQL’과 같습니다. 데이터베이스를 건드릴 때 SQL 한 가지만 알아도 대부분의 작업을 해결할 수 있었듯이, 여기도 물리, 생물, 수학, 통신, 컴퓨터비전 등 다양한 분야를 GPU에서 가속할 수 있는 라이브러리들이 있습니다.
예전에는 ‘쿠다(CUDA)’ 하나라고 부르긴 했지만, 사실 그 위에는 수백 개에 달하는 고수준 라이브러리들이 있는데, 이를 통틀어 ‘쿠다X(CUDA-X)’라고 부릅니다. 현재 전 세계에 수백만 명의 쿠다 개발자가 있고, 이들은 클라우드 서비스, 엔터프라이즈 데이터센터 등 어디서든 GPU 자원을 사용할 수 있기 때문에, 이 라이브러리들로 개발한 애플리케이션은 폭넓은 사용자를 만날 수 있습니다.
저희는 이런 쿠다X 라이브러리를 통해 가속 컴퓨팅의 생태계를 키워왔고, 모든 GTC의 주제 역시 바로 이것이었습니다. 지난 20여 년 간 많은 분들이 쿠다 관련 발표를 들어주셨고, 개발자 여러분 덕분에 여기까지 왔습니다. 여러분 덕분에 인류는 시뮬레이션과 실시간의 경계를 허물고, 물리나 생물, 계산 과학 등을 완전히 새로운 방식으로 바꾸게 됐습니다. 여러분이 ‘인생의 연구(work)를 내 생애 안에 끝낼 수 있게 만들어줬다’고 말해주실 때, 정말 보람을 느낍니다.
다시 한 번 말씀드리지만, 이는 전적으로 여러분 개발자들의 공이고, GTC가 존재하는 이유이기도 합니다. 모두에게 감사드립니다.”
“CUDA는 2006년 세상에 나와, 전 세계 200여 개국 600만 명 이상의 개발자들이 활용해왔습니다. 900개가 넘는 쿠다X 라이브러리와 AI 모델이 등장했고, 수많은 사람이 과학 연구, 산업 혁신, 그리고 기계의 ‘시각·학습·추론’을 가속했습니다. 이제 엔비디아 블랙웰(Blackwell)은 최초의 CUDA GPU보다 최대 5만 배 더 빠른 성능을 보여줍니다. 이같이 지수적으로 늘어난 속도와 확장성은 시뮬레이션과 실시간의 간극을 좁히고, 디지털 트윈까지 실현하고 있습니다. 그리고 아직 이것은 시작에 불과합니다. 다음에는 과연 어떤 혁신이 펼쳐질지, 저희도 기다려집니다.”
“저는 제가 하는 일도 좋지만, 여러분이 그것을 갖고 만들어내는 결과물을 볼 때 가장 큰 기쁨과 감동을 느낍니다. 이렇게 빠른 시간 안에, 이렇게나 많은 업적을 이뤄낸 것은 전적으로 여러분의 덕입니다. 다시 한 번 여러분께 감사드립니다.”
“이제 클라우드에서의 AI 이야기를 해봅시다. 사실 AI는 처음에 클라우드에서 발흥했습니다. 왜냐하면 머신 러닝은 인프라가 필요한데, 클라우드 데이터센터는 이미 인프라를 갖추고 있고, 막강한 소프트웨어 기술자와 연구진이 있으니까요. 이는 AI가 클라우드에서 번영하기에 이상적인 조건이었죠. 그래서 클라우드 서비스 업체(CSP)들은 일찌감치 인공지능에 적극 투자하여 혁신을 주도해왔습니다.

하지만 AI가 점차 더 폭넓게 쓰이게 되면서, 이제 AI는 기업(엔터프라이즈) 전반, 제조 현장, 로보틱스, 자율주행차, 나아가 여러 스타트업이 직접 ‘GPU 클라우드’라는 형태로도 구축됩니다. 코어위브(CoreWeave) 같은 GPU 클라우드 전문 업체가 대표적인 예이며, 이들은 전 세계에 GPU 서버 인프라를 호스팅해 데이터 센터를 운영하죠.
특히, 엣지(Edge) 분야가 아주 중요한데, 오늘 발표에서 언급할 내용 중 하나가 바로 이 부분입니다. 예를 들어, 통신사들의 무선통신망(모바일 랩)만 봐도 전 세계적으로 연간 1천억 달러(약 130조 원) 이상이 투자됩니다. 미래의 네트워크는 당연히 가속 컴퓨팅을 바탕으로 AI가 깊숙이 스며들 것입니다. AI를 통해 빠르게 변하는 신호 환경이나 트래픽 상황을 실시간으로 적응할 수 있게 되고, ‘AI 랸(AI RAN)’이라고 부르는, 소프트웨어 정의(software-defined) 무선 액세스 네트워크가 구현될 수 있습니다.
여기서 라디오는 일종의 로봇이기도 합니다. 수많은 안테나와 방대한 데이터를 다루며, 방향성 빔포밍이나 대규모 MIMO 등에 AI가 개입해 효율을 높이면, 같은 주파수 대역에서도 훨씬 높은 성능을 낼 수 있게 됩니다. 결과적으로 AI는 통신 인프라 또한 크게 바꿀 것입니다.
그래서 오늘 저희는 ‘T-모바일, 시스코, 엔비디아, 시리브러스(Cerebras), ODC’가 손잡고, 완전한 통신용 스택(Full-Stack)을 구축하게 되었다는 소식을 전합니다. 이것이 바로 두 번째 큰 흐름이 될 것입니다. 모든 라디오 네트워크가 가속화되고, AI로 구동되는 시대가 올 겁니다.
이처럼 AI가 모든 산업에 들어가는 것은 확실합니다. 그중에서 하나의 대표적 사례로서 자율주행차를 들 수 있습니다. AI가 퍼지기 시작하자마자, 우리는 ‘알렉스넷(AlexNet)’이 등장했던 순간부터 자율주행차에 몰두하기 시작했습니다. 엔비디아는 벌써 10년 넘게 자율주행차 기술에 매진해왔어요. 오늘날 웨이모(Waymo)나 테슬라(Tesla) 등 거의 모든 자율주행차 기업이 엔비디아 GPU를 사용합니다. 테슬라는 데이터센터에서 엔비디아 GPU를 사용하고, 웨이모는 데이터센터와 차량 양쪽에서 사용합니다.
엔비디아는 자동차 산업을 위해 세 가지 컴퓨터를 제공합니다. 첫째, 학습(트레이닝)용 슈퍼컴퓨터, 둘째, 시뮬레이션용 슈퍼컴퓨터, 셋째, 실제 차량에 탑재되는 ‘로보틱스 컴퓨터’입니다. 거기에 각 계층을 아우르는 소프트웨어 스택과 알고리즘, 모델까지 포함하죠. 그래서 어떤 업체든 자율주행차를 개발하려면, 원하는 대로 엔비디아와 협력할 수 있습니다.

오늘 아주 기쁜 소식은, 제너럴 모터스(GM)가 엔비디아와 협력해 미래의 자율주행차 모델을 개발한다는 점입니다. 정확히 말하면, GM이 엔비디아의 AI 인프라를 도입해 제조, 엔터프라이즈, 그리고 차량 내 탑재용 AI를 모두 아우르는 파트너십을 맺었다는 겁니다. 사실상 GM의 전 AI 분야 파트너가 된 셈이죠.
특히 우리가 자랑스럽게 여기는 것은 ‘안전’(Safety) 분야입니다. 자동차 안전(Safety) 분야에서는 반도체부터 소프트웨어까지, 전 부문에서 다양성(diversity)과 모니터링, 투명성(Transparency), 설명가능성(Explainability)이 요구됩니다. 엔비디아는 이미 700만 줄이 넘는 코드를 안전성 검증을 받았고, 칩, 시스템, 시스템 소프트웨어, 알고리즘 전부가 서드파티를 통해 꼼꼼히 검증되었습니다. 이는 우리만의 ‘NVIDIA Holos(엔비디아 홀로스)’ 프로그램 하에서 이뤄지고, 우리는 1,000건이 넘는 특허를 확보했습니다. 이번 GTC에서도 ‘Holos Workshop’을 진행하니, 꼭 참여해보시길 바랍니다.

홀로스(Holos)야말로 자율주행차가 안전하면서도 고도 자동화된 형태로 나아가기 위한 중요한 토대입니다.
그렇다면, 대부분의 분들이 이미 로보택시나 자율주행차가 어떻게 도로를 달리는지 봐오셨겠지만, 오늘은 엔비디아가 새롭게 접근하고 있는 ‘데이터와 학습’ 문제 해결 방안을 살짝 보여드리려 합니다. 우리는 AI로 AI를 다시 만드는 방식을 채택합니다. 오늘 시연할 영상이 바로 그것입니다.”

“(내레이션) 엔비디아는 옴니버스(Omniverse)와 코스모스(Cosmos)를 활용해 자율주행차 개발을 가속하고 있습니다. 코스모스의 예측 및 추론 기능은 완전한 AI 우선(AI-first) 아키텍처를 뒷받침하며, 모델 디스틸레이션(model distillation), 종단 간(end-to-end) 학습, 클로즈드 루프(closed-loop) 트레이닝, 합성 데이터 생성 등을 통합해 효율적인 개발 환경을 제공합니다.

우선 모델 디스틸레이션부터 보시죠. ‘교사(teacher) 모델’이 더 크고 똑똑한 정책(policy)을 시범으로 보여주면, ‘학생(student) 모델’이 이를 학습해 거의 유사한 성능을 낼 수 있도록 distill(추출)합니다. 이후 주행 환경이 복잡해지면, 클로즈드 루프 트레이닝으로 학생 모델을 세밀하게 보정합니다. 기록(log) 데이터를 3D 장면으로 재구성해 옴니버스 시뮬레이터 안에서 차량이 주행하도록 하고, 코스모스가 그 주행 품질을 평가하죠.
추가로, 합성 데이터 생성을 통해 더 다양한 환경에 유연하게 적응하게 만듭니다. 예컨대 실제 주행 기록을 토대로 얻은 맵, 영상을 옴니버스로 3D 재구성하고, 물체 분할(segmentation) 정보를 씌워 코스모스가 대규모 시나리오를 만들어낼 수 있게 합니다. 이렇게 만들어진 시나리오에서 모델은 계속 학습과 평가를 반복하며, 점점 더 견고한 자율주행 성능을 갖추게 됩니다. 이렇듯 옴니버스와 코스모스는 AI 기반 자율주행차에 학습, 적응, 그리고 지능형 주행 능력을 부여합니다.”
“네, 이런 식으로 ‘AI로 AI를 개발한다(AI creating AI)’는 발상이 엔비디아가 지향하는 바입니다. 시뮬레이션, 합성 데이터, 모델 디스틸레이션, 이런 것들이 결합되어 스스로 상상력을 발휘하는 AI의 발판이 되고, 이를 통해 실제 차량 개발에도 큰 도움이 됩니다.”

“이번에는 데이터센터 이야기를 해보겠습니다. 블랙웰(Blackwell)은 이미 대량 생산(full production)에 들어갔고, 지금 보고 계신 이것이 바로 블랙웰 시스템입니다. 정말 엄청난 기계예요. 우리 엔비디아 같은 사람들에게는 진정한 예술 작품이죠.

여기 보시는 것은, 전 세대 아키텍처와 근본적으로 다른 방식으로 시스템을 재설계한 결과물입니다. 예전에는 ‘HGX’라고 부르는 메인보드에 8개의 GPU가 탑재되어, 그 각각을 NVLink 8로 연결하고, CPU는 별도의 보드로 구성하여 PCI 익스프레스로 연결하는 식이었습니다. HGX 시스템에 CPU 보드를 쌓고, 여러 대가 인피니밴드(infiniband) 스위치를 통해 묶여 슈퍼컴퓨터를 형성했죠.

이것이 우리가 알고 있던 H100(Hopper) 기반의 AI 슈퍼컴퓨터 구성이었는데, 여기서 더 ‘스케일 업(scale-up)’하고 싶어졌습니다. GPU의 개수를 늘려서 거대한 단일 GPU처럼 쓰는 ‘NVLink 32’ 개념을 만들어서 예전에 ‘Ranger’라는 시스템 프로토타입을 보여드렸었죠. 하지만 Ranger는 너무 크고 복잡했습니다. 그래서 우리는 NVLink 스위치 구조부터 완전히 재설계해, 메인보드에서 분리된 독립적인 스위치 모듈(switch tray)로 만들었습니다.

이렇게 스위치를 따로 빼서 랙(rack) 중앙에 배치하고, GPU와 CPU 모듈을 양옆에 배치하는 식으로 구성했어요. 그리고 풀 리퀴드 쿨링(complete liquid cooling)을 적용해, 랙 하나에 어마어마한 양의 컴퓨팅 리소스를 집약할 수 있게 되었죠. 전 세대 시스템만 해도 랙 하나에 들어가는 파츠 개수가 67만 개 수준이었다면, 이제는 6070만 개까지도 증가합니다. 무게도 3천 파운드(약 1.36톤)에 달하고, 케이블 길이만 2마일(약 3.2km)을 넘죠.
이런 식으로 한 랙을 완벽한 컴퓨터 단위로 만들어 ‘1엑사플롭스(ExaFLOPS)급 성능’의 연산을 제공하게 합니다. 엑사플롭스란 1초에 10의 18제곱(1조×1조) 번의 부동소수점 연산을 의미합니다. 그렇게 랙 하나가 완벽한 슈퍼컴퓨터가 되는 거죠. 이를 통해서 ‘스케일 업’과 ‘스케일 아웃(scale-out)’을 동시에 고려할 수 있게 되었습니다.
왜 이렇게 스케일 업이 중요하냐면, 특히 ‘추론(Inference)’ 문제에서 그 필요성이 두드러지기 때문입니다. 추론은 토큰(Token)을 생성하는 과정이고, 토큰은 곧 수익(또는 손실)과 직접적으로 이어집니다. 결국 AI 팩토리(AI 공장)는 얼마나 에너지 효율적으로, 얼마나 많은 토큰을 빠르게 뽑아내느냐가 관건이에요.

그래서 여러분께 한 장의 그래프를 보여드리고자 합니다. 가로축(x축)은 단일 사용자에 대한 토큰 생성 속도(tps, tokens per second)를 뜻하고, 세로축(y축)은 팩토리 전체의 초당 토큰 수를 뜻합니다. 예를 들어, 어떤 사용자가 챗봇에게 질문을 하면 1초에 몇 개의 토큰(단어 비슷한 단위)을 생성해 답할 수 있느냐가 중요하죠. 동시에, 전체 팩토리가 초당 몇 백만, 몇 천만 개의 토큰을 생성해낼 수 있느냐도 중요합니다.
사용자 입장에서는 답이 빠르게 나오면 좋고(높은 tps), 운영자 입장에서는 더 많은 동시 사용자를 처리해 총 토큰 생산량을 늘리고 싶겠죠. 그러나 컴퓨팅 시스템에서는 일괄처리(batch processing)를 많이 하면 전체 처리량은 늘리기 쉬우나 응답 지연이 길어집니다. 반면 실시간으로 빠르게 답하려면(지연 시간을 줄이려면) 전체 처리량이 다소 희생되기도 하죠.
따라서 이 곡선 상에서 왼쪽 아래가 아닌 오른쪽 위에 가까울수록 좋습니다. 즉, 단일 사용자의 응답 속도도 빠르고, 전체 처리량도 높은 이상적인 ‘파레토(Pareto) 프론티어’를 추구하게 됩니다.
이제 호퍼(Hopper)로 그린 곡선을 먼저 보시죠. 8개의 GPU 모듈을 인피니밴드로 묶은 구성이라 가정하고, 전력 1메가와트(MW) 한도로 설정해서 얼마나 많은 토큰을 생성할 수 있는지 시뮬레이션했을 때, 대략 단일 사용자에겐 초당 100토큰 정도까지 가능하고, 전체 합산으로는 초당 250만 토큰(million tokens/sec) 정도에 도달할 수 있다는 결과가 나옵니다.
물론 일괄(batch) 처리를 늘리면 1유저당 응답 시간을 약간 희생하고, 그 대신 1MW 데이터센터가 초당 250만 토큰의 처리량에 도달할 수 있다는 의미입니다. 반대로 즉시 응답을 중시해 일괄 처리를 줄이면, 1유저당 100토큰/초 정도가 가능하나 전체 처리량은 떨어지겠죠. 이 정도가 H100 아키텍처의 대략적 성능 곡선입니다.
그럼 우리는 어떻게 이 곡선을 더 오른쪽 위로 밀어올릴 수 있을까요? 먼저 블랙웰(Blackwell) 아키텍처 자체가 더 빠르고, FP8 정밀도 같은 기술로 더 효율적인 연산을 합니다. 거기에 4비트(4bit) 부동소수점 같은 새로운 정밀도 방식을 적용해 모델을 양자화(quantize)해, 같은 연산량으로 더 많은 토큰을 처리할 수 있게 됩니다.
또 ‘NVLink 72’ 같은 초고속 상호연결(interconnect)을 통해, 여러 GPU를 마치 하나인 것처럼 묶어 거대한 메모리 대역폭과 연산 성능을 확보합니다. 이렇게 고성능 하드웨어가 있어야, 동시에 수많은 토큰을 생성하고, 개인 사용자별로도 지연을 최소화할 수 있습니다.
마지막으로, 진짜 중요한 것은 소프트웨어죠. 여러분이 자주 들어보셨을 ‘텐서 병렬(tensor parallel)’, ‘파이프라인 병렬(pipeline parallel)’, ‘전문가 병렬(expert parallel)’ 등 다양한 방식으로 모델 계산을 분할하고, 사용자 요청이 들어올 때 동적으로 작업량을 조정하며, 심지어 토큰 추론 과정에서 생성된 중간 데이터를 GPU 간에 재할당해야 하는 복잡한 운영 체제가 필요합니다.

이 모든 걸 자동으로 잘 해내는 소프트웨어가 바로 오늘 발표하는 ‘NVIDIA Dynamo’입니다. 이것은 AI 팩토리를 위한 ‘운영체제’(Operating System)나 다름없죠. 전통적인 데이터센터에서 VMware나 쿠버네티스(Kubernetes) 같은 플랫폼이 애플리케이션을 관리했다면, AI 팩토리 시대에는 ‘Dynamo’가 그 역할을 한다고 생각하시면 됩니다. 이를 통해 모델 구성, 배치 방식, 병렬화 전략 등을 실시간에 가깝게 바꿀 수 있어, 앞서 언급한 그래프를 극적으로 개선할 수 있습니다.
우리가 파트너로 삼고 있는 ‘퍼플렉시티(perplexity.ai)’가 대표 사례입니다. 이들은 다이너모를 활용해 AI 서비스의 추론 성능을 최적화하고 있죠. 다이너모는 오픈소스로 제공될 예정이며, AI 팩토리를 구축하려는 누구나 사용할 수 있게 될 겁니다.”

“지금 보시는 그래프가 바로 다이너모와 블랙웰이 결합됐을 때의 파레토 프론티어 변화입니다. 호퍼(Hopper) 기반 대비 최대 25배 이상의 효율을 볼 수 있죠. 1MW 당 토큰 생성량이 2천5백만 개? 혹은 그 이상으로 올라갑니다. 이는 지난해와 비교해 완전히 새로운 차원의 경쟁력이죠.

이제는 어떻게 이런 아키텍처를 실제로 대규모로 배치할 수 있느냐가 관건입니다. 1MW가 아니라 100MW짜리 팩토리를 짓는다고 칩시다. 호퍼로 구성한다면 랙 수가 엄청나게 많아지고, 그 관리가 정말 복잡해질 겁니다. 반면 블랙웰과 다이너모를 활용하면 훨씬 적은 랙으로 같은 전력을 훨씬 더 효율적으로 활용할 수 있게 되죠.
결론적으로, AI 팩토리는 이제부터가 시작입니다. 대규모 추론을 위해서는 초고성능, 초고밀도, 초저전력 구조가 필요하고, 이는 하드웨어부터 소프트웨어까지 전방위 혁신을 요구합니다. 엔비디아는 그 도전에 발 벗고 나섰으며, 이런 이유로 ‘AI 팩토리가 미래의 컴퓨팅 인프라가 될 것’이라고 굳게 믿고 있습니다.”
“AI 팩토리를 건설하려면 막대한 규모의 자본과 인력이 들어갑니다. 그리고 그 건설 과정 자체가 엄청 복잡하죠. 수많은 협력사가 관여해야 하고, 방대한 부품과 어셈블리, 끝없는 케이블 작업, 냉각 시스템, 전력 설비, 네트워킹 토폴로지 등 온갖 요소가 유기적으로 짜여야 합니다. 결국 이 전 과정에서 오류를 줄이고 효율을 높이려면 ‘디지털 트윈(Digital Twin)’이 필수입니다.

우리는 이를 위해 ‘NVIDIA Omniverse Blueprint for AI Factory Digital Twins’를 개발했습니다. AI 공장을 지을 때, 물리적 건설이 시작되기 훨씬 전부터 3D 상에서 미리 완벽하게 설계하고 시뮬레이션할 수 있게 해주는 플랫폼이에요. 그래픽을 통해 그냥 예쁘게만 보는 게 아니라, 실제 공조(air conditioning), 유체 역학, 전기 흐름, 네트워크 레이턴시 등을 전부 물리 기반 시뮬레이션으로 점검할 수 있습니다.

예를 들어, AI 팩토리를 1GW(기가와트) 규모로 지으려 한다고 합시다. 보통 이런 프로젝트에는 건축 설계사, 시공사, 부품 공급사, 설비 엔지니어, 네트워크 전문가 등 어마어마한 수의 인력이 참여하고, 대부분은 각자 다른 소프트웨어를 씁니다. 건물 도면이나 전기 설계, 네트워크 구조, 하드웨어 레이아웃, 냉각 방안 등을 서로 다른 팀이 따로따로 작업하면, 막상 나중에 현장에서 맞춰보는 순간부터 충돌이 생기곤 하죠.

하지만 옴니버스 블루프린트를 쓰면, 모든 팀이 동시에 같은 가상 공간에서 협업할 수 있습니다. 예컨대 설계 정보가 바뀌면 전기 설계 팀도 바로 반영할 수 있고, 네트워크 토폴로지 시뮬레이션 결과가 나오면 냉각 설비 팀도 실시간으로 확인할 수 있어요. 이때 GPU 기반의 물리 시뮬레이션 툴이 병렬로 돌아가므로, 엄청난 규모의 ‘What If(가상 시나리오)’ 테스트를 빠르게 수행합니다.

스냅샷식 ‘단발성 시뮬레이션’이 아니라, 지속적으로 업데이트되고 상호 연결된 ‘디지털 트윈’을 운영하는 것이 핵심입니다. 그러면 인력과 자재를 최적화해 건설 비용과 시간을 단축할 수 있고, 나중에 업그레이드를 하거나 확장을 할 때도 미리 가상의 공장에서 테스트해본 후 착수할 수 있죠.

우리는 엔비디아 내부에서 이미 이런 식으로 차세대 데이터센터와 AI 팩토리를 설계하고 있습니다. 앞서 언급한 ‘버브(Werf), 슈나이더 일렉트릭(Schneider Electric), 에이프(EAP), 케이던스(Cadence)’ 등 각 분야의 주요 업체와 협력해, 공조·냉각·전력·네트워크·레이아웃 시뮬레이션을 옴니버스로 통합 중입니다. 제가 곧 보여드릴 짧은 영상에서 그 모습 일부를 보실 수 있습니다.”

인류는 초대형 AI 팩토리를 건설하기 위해 질주하고 있습니다. 한 AI 기가팩토리를 띄우려면 수백만 종의 부품, 수십만 명의 작업자, 그리고 수십억 달러(또는 그 이상)의 자본이 투입되어야 하죠. 케이블의 총 길이만 지구와 달 사이 거리만큼 될 수도 있습니다.
엔비디아 옴니버스 블루프린트는 이 과정을 디지털 트윈으로 미리 구현할 수 있게 합니다. 여기에 냉각·전력·네트워크 시뮬레이션을 결합해, 물리적 건설 이전에 최적의 구성 방안을 찾을 수 있습니다.
엔비디아 엔지니어들은 옴니버스 블루프린트로 차세대 DGX 슈퍼팟, 최첨단 전력·냉각 설비(버브·슈나이더 일렉트릭), 최적화된 네트워크 구조(에어, Air) 등을 통합해 시각화하고, 협업하며 설계합니다.
보통은 서로 다른 팀들이 별도의 툴로 각각 설계를 진행해, 나중에 현장에서 충돌이 발생하곤 했지만, 옴니버스를 통해 동시에 동일한 3D·시뮬레이션 환경에서 협업함으로써, 건설 착수 전 수많은 시나리오를 빠르게 검증해볼 수 있습니다.
엔비디아 내부에선 케이던스(Cadence)의 현실 디지털 트윈을 이용해 열·유체 역학을 가속하고, 슈나이더 일렉트릭의 EAP로 전력 안전성과 효율성을 시뮬레이션합니다. GPU 기반의 실시간 시뮬레이션 덕분에, 기존에 몇 시간씩 걸리던 계산을 몇 초 안에 수행할 수 있습니다.
또한 디지털 트윈은 완공 후 운영 및 업그레이드 단계에서도 활약합니다. 변경 사항을 적용하기 전에 가상 공간에서 먼저 테스트해보기 때문이죠. 이 모든 과정이 AI 시대의 데이터센터 건설을 혁신하고 있습니다.”
“네, 바로 저 모습이 우리가 그리는 ‘AI 팩토리’의 미래입니다. 디지털 트윈으로 건설 과정을 획기적으로 단축하고, 효율을 높일 수 있죠. 엔비디아 내부에서 이미 이렇게 하고 있으며, 전 세계 주요 파트너사들도 함께 참여해주고 있습니다.
컴퓨팅 역사가 40여 년을 지나오는 동안, 우리가 알고 있던 데이터센터는 어디까지나 범용 CPU와 범용 소프트웨어를 중심으로 하는 구조였어요. 그러나 이제는 뚜렷합니다. ‘AI 팩토리’라고 불릴 정도로, 완전히 다른 방식의 컴퓨팅 인프라가 세계 곳곳에 우후죽순 생겨날 거예요. 저희는 그 길을 최대한 빠르고 안전하게 닦으려 하고, 이 모든 노력이 바로 GTC에서 여러분께 공유되는 것입니다.”
“지금까지 AI 팩토리 이야기를 하면서, 우리가 연간 로드맵을 어떻게 전개해가는지도 말씀드렸습니다. 이제 좀 더 구체적으로 정리해볼게요. 블랙웰(Blackwell)은 현재 대량 생산 중이고, 여러 서버·시스템 제조사들이 대규모로 생산에 돌입하고 있죠.

올해 하반기에는 블랙웰 울트라(Blackwell Ultra) 아키텍처가 이어집니다. 기존 블랙웰과 동일한 시스템 구조를 유지하면서, GPU 칩 자체가 더 빠르고 큰 버전으로 바뀌어요. 1.5배 많은 트랜지스터, 1.5배 큰 메모리, 2배 대역폭, 그리고 주의해야 할 새로운 ‘Attention’ 명령어 등이 추가됩니다. 요약하자면, ‘같은 폼 팩터로 더욱 강력한 GPU’라고 보시면 됩니다.

그 다음 내년(2026)에는 ‘베라 루빈(Vera Rubin)’ 아키텍처로 넘어갑니다. 이름은 천문학자 베라 루빈에서 따왔어요. 그녀는 암흑 물질(Dark Matter)을 발견해낸 전설적인 인물이죠. 베라 루빈 아키텍처에서는 CPU(Grace)와 GPU 모두가 세대 교체되어, 완전히 새로운 칩을 선보입니다. CX9라는 새로운 네트워킹 칩도 등장하고, NVLink 역시 6세대로 진화해 ‘MVLink 144’를 지원합니다.
즉, 올해 하반기에 블랙웰 울트라, 내년 하반기에 베라 루빈, 그리고 그다음에는 베라 루빈 울트라(Vera Rubin Ultra)가 이어지며, 계속해서 스케일 업된 버전을 선보이게 됩니다. 왜 이렇게 매년 새로움을 내놓느냐면, 고객 입장에서는 2~3년 단위로 장기 로드맵을 잡아야 하기 때문입니다. 갑자기 ‘깜짝 출시’를 하면 곤란하기도 하고요.
우리는 대규모 AI 팩토리 구축이라는 중차대한 프로젝트에 맞춰, 한 해에는 네트워크 측면의 혁신, 다음 해에는 GPU 측면의 혁신, 그다음 해에는 시스템 물리 구조의 혁신, 이런 식으로 교차 주기를 두고 있습니다. 그렇게 해야 위험 부담 없이, 혹은 최소화하며 인프라 혁신을 이어갈 수 있으니까요.

그래서 내년(2026) 후반에 나올 ‘베라 루빈 울트라’는 NVLink 576, 즉 더 거대한 스케일 업을 지원하고, 랙 하나가 최대 600kW에 달하는 전력을 소화합니다. 이 하나의 랙에 부품이 250만 개 이상 들어가고, 15엑사플롭스(ExaFLOPS)라는 엄청난 연산 성능을 구현해냅니다. 대역폭은 4,600TB/s(테라바이트/초) 정도로, 모든 게 모두에게 병렬로 연결된 상황을 상상해보시면 됩니다.

정리하자면, 블랙웰 -> 블랙웰 울트라 -> 베라 루빈 -> 베라 루빈 울트라 순으로 연간 업데이트가 이뤄지고, 매번 ‘X배 더 커지고 빨라지는’ 변화를 예고하고 있습니다. 이처럼 엔비디아는 계속해서 세계 최고 성능의 스케일업 시스템을 만들겠다는 비전을 갖고 있습니다.

또 하나 중요한 게, 스케일 아웃(scale-out)에 대해서도 이야기해야 한다는 점입니다. 랙 내부적으로는 NVLink라는 초고속 스위치 구조를 쓰고, 랙 간 혹은 데이터센터 전체 차원에서는 ‘인피니밴드(Infiniband)’와 ‘스펙트럼X(Spectrum-X)’ 이더넷 솔루션을 사용하죠. 그런데 정말 거대한 규모로 확장하려면, 지금처럼 광트랜시버(transceiver) 하나당 30W씩 소모하는 방식으로는 한계가 있습니다.


가령 GPU가 10만 개, 20만 개 모인 데이터센터를 생각해봅시다. 각 GPU가 6~8개의 광모듈을 달고, 모듈 하나가 수십 W씩 먹는다면, 전력 소모가 너무 커집니다. 그래서 우리는 ‘실리콘 포토닉스(silicon photonics)’와 co-packaged optics 기술을 적극 개발하고 있어요. 그동안 수백 건의 특허를 출원했고, 대만 TSMC를 비롯해 많은 파트너들과 함께 신기술을 실리콘 웨이퍼 위에서 구현해왔습니다.

그 결과, 마이크로 링 공진(micro ring resonator) 방식의 MRM이라는 광 모듈을 개발해 전력 소모를 크게 줄이고, 일체형으로 조립된 CPO(Co-Packaged Optics) 스위치를 만들고 있습니다. 이렇게 하면 1.6Tbps급(초당 1.6테라비트) 전송도 가능하고, 모듈 하나당 30W 소모하던 걸 훨씬 낮출 수 있습니다.
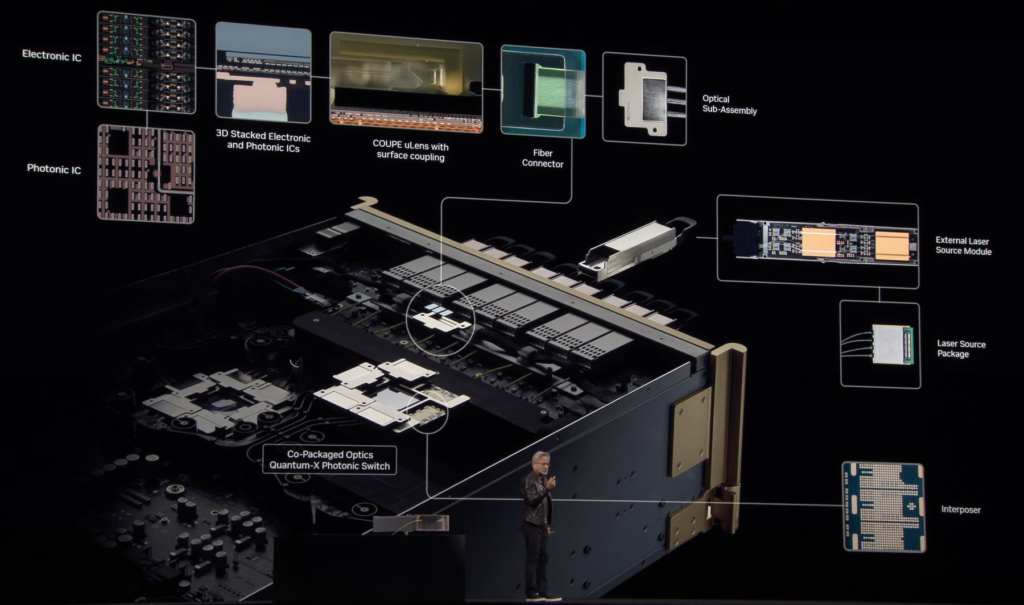
스위치 모듈 하나에 512개 포트를 밀집시킨다든지, GPU 쪽에도 궁극적으로는 이런 실리콘 포토닉스 기반 옵틱을 바로 장착하게 함으로써, 만 대~수십만 대의 GPU가 랙과 랙, 데이터센터와 데이터센터를 광케이블로 저전력, 고대역폭으로 연결할 수 있게 됩니다. 이게 바로 초대형 스케일 아웃 시대를 대비하는 핵심 기술이죠.




그래서 저희가 그 이름을 ‘Miranda(미란다)’라고 부릅니다. 2027년 경에 미란다 스위치가 준비되어, 그때쯤엔 베라 루빈 울트라와 결합해 훨씬 더 거대한 규모의 GPU 클러스터가 가능해질 겁니다. 이런 로드맵을 한꺼번에 보여드리는 이유는, AI 팩토리를 건설하려는 분들이 지금부터 몇 년 뒤, 혹은 더 먼 미래까지 체계적으로 준비할 수 있도록 하기 위함입니다.”
“이제 엔터프라이즈 컴퓨팅에 관해 이야기를 옮겨가 봅시다. 우리가 인공지능(AI)을 온전히 기업 세계로 가져오려면, 다시 한 번 전체 스택의 혁신이 필요합니다. AI는 클라우드에서도 잘 작동하지만, 기업마다 워크로드 형태나 소프트웨어 환경, 거버넌스 요구사항 등이 모두 다르므로, 독립적인 온프레미스(On-Prem) AI 인프라가 필수적으로 필요해집니다.

그래서 우리는 엔터프라이즈를 위한 전용 서버부터, 워크스테이션, 슈퍼컴퓨터까지 다양하게 준비하고 있습니다. 가장 작은 형태가 바로 ‘DGX 스테이션(DGX Station)’인데, 이를 흔히 ‘개인용 슈퍼컴퓨터’라고 부르기도 합니다. GPU 4개가 NVLink로 연결된 미니 탑 구조이고, 여기에 Grace CPU 72코어, HBM 메모리 등을 탑재하여, 단순히 CPU 중심 워크스테이션과는 비교가 안 될 정도로 높은 AI 성능을 갖춥니다.

그 다음이 ‘DGX 서버’ 계열이고, 더 나아가 여러 대의 DGX 서버를 묶어 만든 ‘DGX 슈퍼팟(SuperPOD)’이 있죠. 이 모든 라인업을 Dell, HPE, 레노버(Lenovo), Asus 등 다양한 OEM이 제조·공급하고 있으며, 각 기업 환경에 맞춰 구성할 수 있습니다.

또 하나 중요한 변화가 있습니다. AI 네트워크(Accelerated Network)와 AI 스토리지(Accelerated Storage) 역시 완전히 달라집니다. 전통적인 파일 서버나 블록 스토리지, SAN, NAS 개념을 넘어, 이제는 데이터 자체를 ‘시맨틱(semantic)’ 방식으로 조회하고, AI 모델이 즉시 접근해 해답을 찾아내야 하죠. 예를 들어, 회사 내 문서·PDF·보고서 등이 전부 모여 있는 스토리지라면, 과거에는 검색어로 일일이 검색해서 문서를 열어 확인해야 했지만, 앞으로는 AI가 데이터에 직접 질의하여 원하는 정보를 곧바로 답해줄 겁니다.

그래서 ‘파일 수준’이 아니라, ‘데이터 의미(시맨틱) 수준’에서 인덱싱하고 임베딩(embedding)하는 기능이 필요해집니다. 새로운 형태의 GPU 가속 스토리지가 탄생하는 이유죠. 이미 박스(Box), Pure Storage, VAST, NetApp, Hitachi, IBM, Dell, HPE 등 스토리지 전문기업과의 협력이 활발히 진행 중이며, ‘Nvidia AI-Ready Storage’라는 이름으로 시장에 나오게 됩니다.
그러니까 엔터프라이즈 IT 스택의 세 축—컴퓨팅(서버), 네트워킹, 스토리지—모두가 AI 시대로 재설계되는 것이죠. 제 동료 마이클(Michael)이 보여준 한 장의 슬라이드가 이를 잘 요약해줍니다. Dell 테크놀로지스를 예로 들면, Dell은 Dell PowerEdge 서버 + Nvidia GPU + Spectrum-X 네트워크 + AI-Ready 스토리지 + Nvidia 소프트웨어 스택을 하나로 묶은 종합 패키지를 출시합니다. 이렇듯 HP, 레노버 등 OEM 파트너사들도 같은 형태로 엔터프라이즈용 AI 솔루션을 선보일 겁니다.
한편, 오늘 특별히 말씀드리고 싶은 것은 새로운 거대 언어모델(LLM)인 ‘NEMS’(Nvidia Enterprise Model Stack)를 공개한다는 사실입니다. 앞서 시연에서 보여드린 R1 모델(추론/Reasoning용 모델) 수준의 성능을, 기업이 직접 온프레미스나 프라이빗 클라우드에서 사용하기 쉽게 만든 것이죠.
‘NEMS’는 완전히 오픈소스로 제공되고, DGX 스파크(Spark)나 DGX 스테이션, 혹은 OEM 서버 등 어디서든 구동 가능합니다. 또한 프리트레인(pre-train)된 모델이지만, 기업의 도메인 데이터로 추가 파인튜닝(fine-tuning)하거나, 사내 정보에 접속해 문서를 요약·분석하는 등 다양한 기능을 수행할 수 있습니다. 보안과 프라이버시 측면에서 민감한 기업 데이터가 대외로 유출되지 않도록, 사내 인프라에서만 모델을 운영할 수 있다는 점이 강력한 이점이 되겠죠.
이렇게 엔비디아는 ‘엔터프라이즈 AI’를 위해 필요한 모든 요소—GPU 서버, 네트워크, 스토리지, 소프트웨어 스택, 그리고 준비된 LLM까지—토털 솔루션을 제공하게 됩니다. 내년이면 이런 엔비디아 엔터프라이즈 AI 스택이 본격적으로 시장에 풀릴 것이고, 여러분이 속한 조직에서도 충분히 도입할 수 있을 것입니다.”
“다음으로, 우리는 AI가 이미 ‘개인 비서’ 수준을 넘어, ‘에이전트(Agent)’로 발전할 수 있음을 봤습니다. 에이전트형 AI는 맥락(context)을 파악하고, 일련의 작업을 스스로 설계·계획하여 수행할 수 있게 됩니다. 이런 시나리오는 엄청나게 많습니다. 예를 들어, 고객 지원 업무에서 단순 FAQ를 넘어서, 실제로 회사 내부 IT 시스템에 접근해 문제를 해결해준다거나, 설정을 변경한다거나 하는 식이죠.
그렇다면 이것은 결국 ‘소프트웨어 개발 방식’도 바꾸게 됩니다. 전통적인 소프트웨어는 사람이 코드를 짜고, 그 코드를 컴퓨터가 실행하는 구조였지만, 이제는 사람이 간단한 요구사항만 말하면, AI가 자체적으로 코드를 생성하고, 실행 중 발생하는 오류를 잡아내며, 심지어 다른 API나 툴을 찾아서 통합하는 일까지 가능해집니다.
그래서 이른바 ‘에이전트급 LLM’(Large Language Model)의 존재가 더 커지고 있고, 우리 엔비디아 역시 이 영역에 큰 관심이 있습니다. 방금 소개해드린 엔터프라이즈용 모델 스택 ‘NEMS’에도, 이런 에이전트 기능을 활용할 수 있는 컴포넌트가 포함되어 있어요.
예컨대 기업 내 구식 ERP 시스템이 있다고 합시다. 보통은 사용자가 복잡한 인터페이스를 통해 수많은 메뉴를 뒤져야 정보를 얻을 수 있죠. 그런데 에이전트형 AI가 ERP 시스템의 API 문서를 읽고, 필요한 호출 방식을 익힌 뒤, 사용자의 질문 의도를 파악해 ERP에서 데이터를 추출하고, 요약·분석하여 곧바로 결과를 내줄 수 있습니다. 마치 사람이 ‘야, 전년 대비 매출 증가율하고, 그 원인 좀 분석해줘’라고 말하면, 에이전트가 직접 ERP를 조작해 필요한 데이터를 모으고, 그걸 바탕으로 원인을 찾아내 요약해 주는 식이죠.
이것이 바로 ‘툴 사용 능력’을 갖춘 에이전트형 AI의 진정한 위력입니다. 그래서 기존의 RPA(Robotic Process Automation) 솔루션, ERP, CRM, IT 관리 툴, 그리고 온갖 SaaS 서비스들이 AI와 결합할 여지가 큽니다. 엔비디아가 엔터프라이즈 AI 스택을 내놓는 것도, 결국 이러한 거대한 변화를 염두에 둔 것입니다.

이제 곧 각 기업들은 ‘AI 보조 인력’을 무수히 거느리게 될 것입니다. 과거에는 이런 걸 두고 ‘디지털 워커(digital worker)’라고 불렀는데, 이제는 그보다 훨씬 똑똑합니다. 말 그대로 연산 능력의 한계가 허용하는 선에서, 매우 빠르게 학습하고 답을 제시하고, 도구를 사용할 수 있으며, 협업까지 가능합니다. 그리고 그 모든 것이 특정 애플리케이션 하나가 아니라, 통합된 AI 스택과 LLM 위에서 돌아가게 될 겁니다.

다만, 이렇게 새로운 시대가 열리려면, 데이터와 모델, 코드, 보안, 인프라 등 모든 측면에서 준비가 되어야 합니다. 예컨대, 기업 데이터가 외부로 유출되면 안 되므로 사내 혹은 프라이빗 클라우드 환경에서 모델을 운영해야 하고, 기존 시스템과 연결할 수 있는 API 문서를 잘 정비해야 합니다. 무엇보다도, 우리가 반복해서 말했듯 대규모 학습 및 추론을 감당할 수 있는 가속 컴퓨팅 인프라가 깔려 있어야 합니다.

결국, 다음 5년 안에 엔터프라이즈 컴퓨팅 landscape는 완전히 재편될 것이고, 그 중심에는 AI와 가속 컴퓨팅이 자리 잡을 것입니다. 여러분은 이미 그 변화를 체감하고 계실지도 모르겠습니다. 하루빨리 준비를 시작해야 합니다.”

“그렇다면 ‘AI가 기업 업무 전체를 재편한다’는 이야기로 넘어가기 전에, 엔비디아 내부에서도 ‘AI로 AI를 만든다(AI creating AI)’는 프로젝트를 진행 중임을 다시 한 번 강조하고 싶습니다. 우리는 이미 이 방식으로 소프트웨어를 개발하고, 시스템을 설계하고, 심지어는 회로 설계와 반도체 생산에도 적용하고 있습니다.
예를 들어, EDA(전자설계자동화) 분야만 해도, 과거에는 CPU 기반 툴로 몇 주, 몇 달이 걸리던 시뮬레이션이나 검증 작업이 GPU 가속으로 단축되었고, 거기에 AI가 추가로 더해져 특정 영역을 자동 탐색하거나, 설계 공간을 최적화하는 식으로 혁신하고 있습니다. 결국 ‘가속 컴퓨팅 + AI + 합성 데이터 + 시뮬레이션’이 결합된 형태죠.

이처럼 AI가 도입될 수 있는 분야는 정말 무궁무진합니다. 이제부터는 기업과 산업 전반에 걸쳐, AI가 일상적 도구가 될 것입니다. 이런 흐름에 힘입어, AI 팩토리를 주축으로 하는 글로벌 데이터센터 인프라가 거대하게 성장할 것이고, 앞서 말씀드린 ‘AI 팩토리 디지털 트윈’도 관련 업계를 혁신할 겁니다.
제가 늘 강조하지만, 엔비디아 혼자만으로는 불가능합니다. 수많은 파트너, 개발자, 연구자, 기업, 정부가 함께 참여해 생태계를 만들고 있지요. GTC야말로 그 만남의 장이자, 최신 혁신을 공유하는 축제라고 할 수 있습니다. 여기서는 거의 모든 산업에 걸친 AI 적용 사례와 성공 스토리가 쏟아지고, 그야말로 ‘슈퍼볼’ 같은 축제 분위기가 연출됩니다.
우리는 지금 거대한 변화의 초입에 서 있습니다. 디지털 혁명은 이제 검색 기반(retrieval-based)을 넘어 생성 기반(generative)으로 진화했고, 한 걸음 더 나아가 에이전트(Agent) 수준으로 발전 중입니다. 그리고 물리적 AI(physical AI)가 로보틱스 혁명을 일으킬 것입니다. 각 단계마다 엄청난 규모의 연산 자원이 필요하고, 데이터센터가 AI 팩토리로 거듭나는 데에도 이 생태계 모두가 함께 협력해야 합니다.
앞으로 남은 발표 세션에서는 엔비디아가 준비한 기술 데모와 주요 파트너들의 사례 발표가 이어질 겁니다. 물리 시뮬레이션부터 합성 데이터, 에이전틱 AI 개발 프레임워크, 엣지 컴퓨팅, 자율주행, 의료, 클라우드 네이티브, 그리고 방대한 엔터프라이즈 애플리케이션까지… 분야가 너무나 다양합니다.
여러분 모두가 이러한 로드맵과 생태계가 만들어가는 ‘AI의 미래’를 함께 공유하고, 각자의 자리에서 새로운 혁신을 시도하시길 바랍니다. 그리고 그 결과물을 꼭, 내년에 열릴 GTC에서 다시 보여주셨으면 좋겠습니다.”

여기까지가 제가 오늘 여러분께 꼭 전해드리고 싶었던 이야기의 핵심입니다. 우리는 GPU를 통해 ‘가속 컴퓨팅’을 개척했지만, 그 길 끝에 ‘인공지능 혁명’이 기다리고 있을 줄은 상상조차 못 했습니다.
물론 우리가 어느 정도 AI의 잠재력을 예견했을 수 있겠지만, 지금처럼 전 세계가 AI로 뒤흔들릴 정도라고는 생각하기 어려웠죠. 이제는 AI가 완전히 상식적인 존재가 됐고, 모든 곳에서 AI를 사용하려 합니다.
마지막으로, 몇 가지 마무리 말씀을 드리고 싶습니다. 첫째, 여러분 모두 AI를 ‘사이드 프로젝트’ 정도로 여기지 않고, 핵심 역량으로 삼으시라는 겁니다. 왜냐하면 이건 한때 유행하다 마는 트렌드가 아니라, 불가역적인 패러다임 변화이기 때문이죠.
둘째, AI는 다른 이들의 지식을 빌려 쓰는 형태가 아니라, 스스로 학습하고 성장해야 합니다. 그러려면 가속화된 데이터센터가 필요합니다. 기하급수적으로 성장하는 연산 수요를 감당하지 못하면, 기업 활동에 심각한 지장이 생길 겁니다.
셋째, 이미 AI를 한참 활용하고 있는 곳에서도 한 번 돌아보시길 바랍니다. 지금의 AI 활용 방식이 최선인지, 더 개선할 수 있는 부분은 없는지, 혹은 새로운 가능성은 없는지 말이죠. 아직도 우리는 AI의 잠재력 일부만 실현하고 있을 뿐입니다.
마지막으로, GTC는 여기서 끝이 아니에요. 이곳 오프라인 행사장뿐 아니라, 온라인으로도 수많은 세션이 진행됩니다. 전 세계 연구자, 엔지니어, 스타트업, 대기업, 그리고 교육 분야, 정부기관까지 정말 다양합니다. 각 세션에서 훨씬 구체적인 기술, 구현 사례, 그리고 라이브 데모를 보실 수 있을 겁니다.
여러분이 시간을 내서 꼭 관심 있는 분야를 살펴보시길 바랍니다. 그리고 가능하다면 우리 개발자 생태계에 직접 기여해주시면 좋겠어요. CUDA-X 라이브러리를 개선하거나, 오픈소스 프로젝트에 참여하거나, 새로운 AI 모델을 공개하거나 하는 식으로 말이죠.
저는 곧 여기 무대를 정리하고, 여러 세션을 통해 다시 모습을 드릴 겁니다. 여러분과 함께, 미래로 가는 길을 한 걸음씩 닦아나가길 고대합니다. 고맙습니다.”


Pingback: 인공지능 AI 뉴스 - 2025년 3월 19일 - AutoAIDaily